










 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


什么是网络爬虫?网络爬虫有哪些用途?
更新时间:2021年05月06日17时48分 来源:传智教育 浏览次数:

网络爬虫,又称为网页蜘蛛、网络机器人,是一种按照一定的规则,自动请求万维网网站并提取网络数据的程序或脚本。
如果说网络像一张网,那么爬虫就是网上的一只小虫子,在网上爬行的过程中遇到了数据,就把它抓取下来。
这里的数据是指互联网上公开的并且可以访问到的网页信息,而不是网站的后台信息(没有权限访问),更不是用户注册的信息(非公开的)。
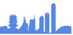
爬虫具体能做些什么呢?接下来,我们通过一张图来总结网络爬虫的常用功能,如图1所示。

图1 爬虫的常用功能
图1列举了一些网络爬虫常用的功能。由该图可知,通过网络爬虫可以代替手工完成很多事情。例如,使用网络爬虫搜集金融领域的数据资源,将金融经济的发展与相关数据进行集中处理,能够为金融领域的各个方面如经济发展趋势、金融投资、风险分析等提供“数据平台”。
或者,浏览网页上的信息时,会看到上面有很多广告信息,十分扰人。这时,可以利用网络爬虫将网页上的信息全部爬取下来,自动过滤掉这些广告,便于对信息的阅读。
再者,我们想从某个网站中购买商品,需要知道诸如畅销品牌、价格走势等信息。对于非网站管理员而言,手动统计是个很大的工程。这时,可以利用网络爬虫轻松地采集到这些数据,以便做出进一步的分析。
再比如,你想推销一些理财产品,需要找到一些目标客户和他们的联系方式。这时,可以利用网络爬虫设置对应的规则,自动从互联网中采集到目标用户的联系方式等,以进行营销使用。
总而言之,从互联网中采集信息是一项重要的工作,如果单纯地靠人力进行信息采集,不仅低效繁琐,而且花费成本高。爬虫的出现在一定的程度上代替了手工访问网页,能够实现自动化采集互联网的数据,以更高地效率去利用互联网中的有效信息。
猜你喜欢:
最新资讯




















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
