










 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


推荐系统是什么
更新时间:2015年12月29日16时08分 来源:传智播客云计算学科 浏览次数:
推荐系统是什么
为了解决信息过载和用户无明确需求的问题,找到用户感兴趣的物品,才有了个性化推荐系统。其实,解决信息过载的问题,代表性的解决方案是分类目录和搜索引擎,如hao123,电商首页的分类目录以及百度,360搜索等。不过分类目录和搜索引擎只能解决用户主动查找信息的需求,即用户知道自己想要什么,并不能解决用户没用明确需求很随便的问题。
典型随便用户的经典对话是:你想吃什么,随便!
面对这种很随便又得罪不起的用户(女友和上帝),只能通过分析用户的历史行为给用户的兴趣建模,从而主动给用户推荐能够满足他们兴趣和需求的信息。比如问问女友的闺蜜,她一般什么时候喜欢吃什么。该闺蜜因为长期和女友在一起对她经常吃什么买什么有足够的认识,从而给他打标签,然后通过大脑建模,最后给她推荐。
下图是一个简单的推荐系统结构图,日志系统获取用户的行为信息,推荐系统根据用户行为信息进行推荐。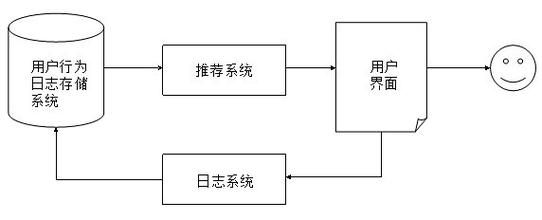
推荐系统广泛存在于各类网站中,作为一个应用为用户提供个性化的推荐。它需要一些用户的历史数据,一般由三个部分组成:基础数据、推荐算法系统、前台展示。基础数据包括很多维度,包括用户的访问、浏览、下单、收藏等等很多信息;推荐算法系统主要是根据不同的推荐诉求有多个算法组成的推荐模型;前台展示主要是对客户端系统进行响应,返回相关的推荐信息以供展示。
迄今为止,在个性化推荐系统中,协同过滤技术是应用最成功的技术。目前国内外有许多大型网站应用这项技术为用户更加智能的推荐内容。协同过滤算法有两种,一种是基于用户的协同过滤,另外一种是基于商品的协同过滤。
第一代协同过滤技术是基于用户的协同过滤算法,基于用户的协同过滤算法在推荐系统中获得了极大的成功,但它有自身的局限性。因为基于用户的协同过滤算法先计算的是用户与用户的相似度(兴趣相投,人以群分物以类聚),然后将相似度比较接近的用户A购买的物品推荐给用户B,专业的说法是该算法用最近邻居(nearest-neighbor)算法找出一个用户的邻居集合,该集合的用户和该用户有相似的喜好,算法根据邻居的偏好对该用户进行预测。
基于用户的推荐逻辑有两个问题:冷启动与计算量巨大。基于用户的算法只有已经被用户选择(购买)的物品才有机会推荐给其他用户。在大型电商网站上来讲,商品的数量实在是太多了,没有被相当数量的用户购买的物品实在是太多了,直接导致没有机会推荐给用户了,这个问题被称之为协同过滤的“冷启动”。另外,因为计算用户的相似度是通过目标用户的历史行为记录与其他每一个用户的记录相比较的出来的,对于一个拥有千万级活跃用户的电商网站来说,每计算一个用户都涉及到了上亿级别的计算,虽然我们可以先通过聚类算法经用户先分群,但是计算量也是足够的大。
下图是基于用户的协同过滤算法,该图片来自百度图片。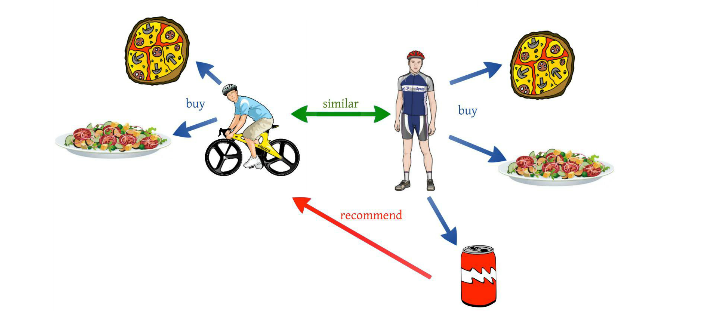
第二代协同过滤技术是基于物品的协同过滤算法,基于物品的协同过滤算法与基于用户的协同过滤算法基本类似。他使用所有用户对物品或者信息的偏好,发现物品和物品之间的相似度,然后根据用户的历史偏好信息,将类似的物品推荐给用户。这听起来比较拗口,简单的说就是几件商品同时被人购买了,就可以认为这几件商品是相似的,可能这几件商品的商品名称风马牛不相及,产品属性有天壤之别,但通过模型算出来之后就是认为他们是相似的。什么?你觉得不可思议,无法理解。是的,就是这么神奇!
举个例子:假设用户 A 喜欢物品 A 和物品 C,用户 B 喜欢物品 A,物品 B 和物品 C,用户 C 喜欢物品 A,从这些用户的历史喜好可以分析出物品 A 和物品 C 时比较类似的,喜欢物品 A 的人都喜欢物品 C,基于这个数据可以推断用户 C 很有可能也喜欢物品 C,所以系统会将物品 C 推荐给用户 C。
下图是基于物品的协同过滤算法,该图片来自百度图片。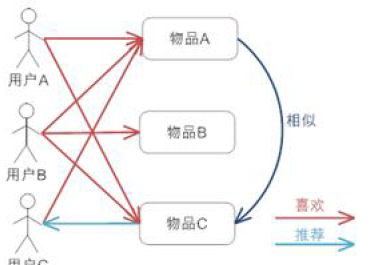
基于物品的协同过滤推荐机制是 Amazon 在基于用户的机制上改良的一种策略,因为在大部分的 Web 站点中,物品的个数是远远小于用户的数量的,而且物品的个数和相似度相对比较稳定,同时基于物品的机制比基于用户的实时性更好一些。但也不是所有的场景都 是这样的情况,可以设想一下在一些新闻推荐系统中,也许物品,也就是新闻的个数可能大于用户的个数,而且新闻的更新程度也有很快,所以它的形似度依然不稳 定。
通过介绍以上两种协同过滤,可以推荐策略的选择其实和具体的应用场景有很大的关系。下面是我对推荐系统的几点总结,供大家参考:
1) 推荐系统分为在线推荐系统和离线推荐系统,在电商领域对推荐的时效性要求相对较高,在线推荐系统逐渐成为主流。
2) 推荐系统的一般流程:数据产生、数据准备、数据清洗、数据存储、算法计算、推荐数据、规则混合排序、周期性重复以上过程。
3) 不能做规则定制的推荐系统不是一个好的推荐系统,算法有时候跑出来的结果并不是很理想,需要通过业务人员定义的规则改善推荐效果。如季节性产品、习大大等热点。除此之外,也可以方便业务人员增加硬推,硬推包括广告和导向。
4) 推线系统上线之前,需要做效果测试,一般使用AB Test。测试一个推荐系统的好坏,在学术领域是看准确率,但在业务领域是看的转化率,效果效果效果。另外AB测试本身的就是一个很具有几率性的问题,因为流量的分配是随机不确定的,在大型电商中流量就是金钱,拿线上流量做测试是一件非常可耻可耻的事情。
5) 光明和黑暗是相生相伴的,有推荐的地方就是刷子。从最开始的浏览、点击、订单、评价等基础数据开始刷,到后期直接刷推荐效果,这对推荐系统的考验比较大。比较有效的方式之一是在数据清洗阶段通过规则将刷子的账号过滤出去,如何过滤刷子又是一个涉及到防作弊的巨大工程。
6) 不同的推荐位的诉求不同,推荐的产品也不同,学习推荐系统,算法、模型、数据都是很重要的。但更重要的不是算法、模型、数据本身,而是追求对模型的透彻理解以及业务需求的把握,也就是根据业务的不同,选择不同的合适的算法和模型。
为了解决信息过载和用户无明确需求的问题,找到用户感兴趣的物品,才有了个性化推荐系统。其实,解决信息过载的问题,代表性的解决方案是分类目录和搜索引擎,如hao123,电商首页的分类目录以及百度,360搜索等。不过分类目录和搜索引擎只能解决用户主动查找信息的需求,即用户知道自己想要什么,并不能解决用户没用明确需求很随便的问题。
典型随便用户的经典对话是:你想吃什么,随便!
面对这种很随便又得罪不起的用户(女友和上帝),只能通过分析用户的历史行为给用户的兴趣建模,从而主动给用户推荐能够满足他们兴趣和需求的信息。比如问问女友的闺蜜,她一般什么时候喜欢吃什么。该闺蜜因为长期和女友在一起对她经常吃什么买什么有足够的认识,从而给他打标签,然后通过大脑建模,最后给她推荐。
下图是一个简单的推荐系统结构图,日志系统获取用户的行为信息,推荐系统根据用户行为信息进行推荐。
推荐系统广泛存在于各类网站中,作为一个应用为用户提供个性化的推荐。它需要一些用户的历史数据,一般由三个部分组成:基础数据、推荐算法系统、前台展示。基础数据包括很多维度,包括用户的访问、浏览、下单、收藏等等很多信息;推荐算法系统主要是根据不同的推荐诉求有多个算法组成的推荐模型;前台展示主要是对客户端系统进行响应,返回相关的推荐信息以供展示。
迄今为止,在个性化推荐系统中,协同过滤技术是应用最成功的技术。目前国内外有许多大型网站应用这项技术为用户更加智能的推荐内容。协同过滤算法有两种,一种是基于用户的协同过滤,另外一种是基于商品的协同过滤。
第一代协同过滤技术是基于用户的协同过滤算法,基于用户的协同过滤算法在推荐系统中获得了极大的成功,但它有自身的局限性。因为基于用户的协同过滤算法先计算的是用户与用户的相似度(兴趣相投,人以群分物以类聚),然后将相似度比较接近的用户A购买的物品推荐给用户B,专业的说法是该算法用最近邻居(nearest-neighbor)算法找出一个用户的邻居集合,该集合的用户和该用户有相似的喜好,算法根据邻居的偏好对该用户进行预测。
基于用户的推荐逻辑有两个问题:冷启动与计算量巨大。基于用户的算法只有已经被用户选择(购买)的物品才有机会推荐给其他用户。在大型电商网站上来讲,商品的数量实在是太多了,没有被相当数量的用户购买的物品实在是太多了,直接导致没有机会推荐给用户了,这个问题被称之为协同过滤的“冷启动”。另外,因为计算用户的相似度是通过目标用户的历史行为记录与其他每一个用户的记录相比较的出来的,对于一个拥有千万级活跃用户的电商网站来说,每计算一个用户都涉及到了上亿级别的计算,虽然我们可以先通过聚类算法经用户先分群,但是计算量也是足够的大。
下图是基于用户的协同过滤算法,该图片来自百度图片。
第二代协同过滤技术是基于物品的协同过滤算法,基于物品的协同过滤算法与基于用户的协同过滤算法基本类似。他使用所有用户对物品或者信息的偏好,发现物品和物品之间的相似度,然后根据用户的历史偏好信息,将类似的物品推荐给用户。这听起来比较拗口,简单的说就是几件商品同时被人购买了,就可以认为这几件商品是相似的,可能这几件商品的商品名称风马牛不相及,产品属性有天壤之别,但通过模型算出来之后就是认为他们是相似的。什么?你觉得不可思议,无法理解。是的,就是这么神奇!
举个例子:假设用户 A 喜欢物品 A 和物品 C,用户 B 喜欢物品 A,物品 B 和物品 C,用户 C 喜欢物品 A,从这些用户的历史喜好可以分析出物品 A 和物品 C 时比较类似的,喜欢物品 A 的人都喜欢物品 C,基于这个数据可以推断用户 C 很有可能也喜欢物品 C,所以系统会将物品 C 推荐给用户 C。
下图是基于物品的协同过滤算法,该图片来自百度图片。
基于物品的协同过滤推荐机制是 Amazon 在基于用户的机制上改良的一种策略,因为在大部分的 Web 站点中,物品的个数是远远小于用户的数量的,而且物品的个数和相似度相对比较稳定,同时基于物品的机制比基于用户的实时性更好一些。但也不是所有的场景都 是这样的情况,可以设想一下在一些新闻推荐系统中,也许物品,也就是新闻的个数可能大于用户的个数,而且新闻的更新程度也有很快,所以它的形似度依然不稳 定。
通过介绍以上两种协同过滤,可以推荐策略的选择其实和具体的应用场景有很大的关系。下面是我对推荐系统的几点总结,供大家参考:
1) 推荐系统分为在线推荐系统和离线推荐系统,在电商领域对推荐的时效性要求相对较高,在线推荐系统逐渐成为主流。
2) 推荐系统的一般流程:数据产生、数据准备、数据清洗、数据存储、算法计算、推荐数据、规则混合排序、周期性重复以上过程。
3) 不能做规则定制的推荐系统不是一个好的推荐系统,算法有时候跑出来的结果并不是很理想,需要通过业务人员定义的规则改善推荐效果。如季节性产品、习大大等热点。除此之外,也可以方便业务人员增加硬推,硬推包括广告和导向。
4) 推线系统上线之前,需要做效果测试,一般使用AB Test。测试一个推荐系统的好坏,在学术领域是看准确率,但在业务领域是看的转化率,效果效果效果。另外AB测试本身的就是一个很具有几率性的问题,因为流量的分配是随机不确定的,在大型电商中流量就是金钱,拿线上流量做测试是一件非常可耻可耻的事情。
5) 光明和黑暗是相生相伴的,有推荐的地方就是刷子。从最开始的浏览、点击、订单、评价等基础数据开始刷,到后期直接刷推荐效果,这对推荐系统的考验比较大。比较有效的方式之一是在数据清洗阶段通过规则将刷子的账号过滤出去,如何过滤刷子又是一个涉及到防作弊的巨大工程。
6) 不同的推荐位的诉求不同,推荐的产品也不同,学习推荐系统,算法、模型、数据都是很重要的。但更重要的不是算法、模型、数据本身,而是追求对模型的透彻理解以及业务需求的把握,也就是根据业务的不同,选择不同的合适的算法和模型。
最新资讯
相关阅读
0
分享到:




















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
